
はじめに
Kinesis Data Streams をがっつり扱う機会があったので、Kinesis Data Streams を使用する際の勘所を備忘録としてまとめます。 公式ドキュメントに沿って整理していきます。
Kinesis Data Streams の用語と概念
Kinesis Data Stream
Kinesis Data Streamはシャード(詳細は後述)の集合で構成されています。データレコードは各シャード内で順序が保証されます。ドキュメント上ではデータストリームと表記されることが多いです。
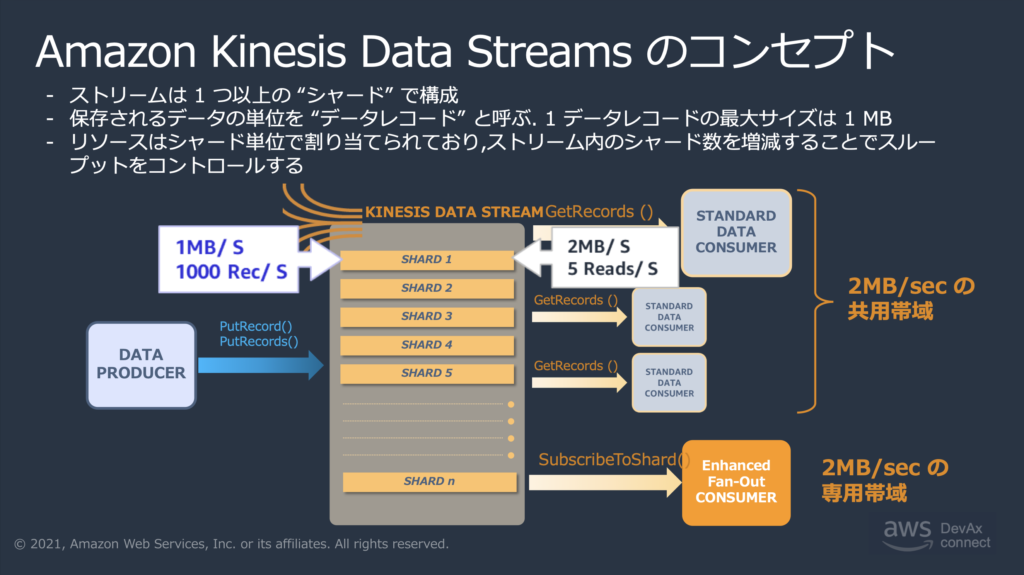
DevAx::connectシーズン 1「イベント駆動」第5回 Near Real-Time Analytics を実現するアーキテクチャーと実装より抜粋
データレコード
データレコードはシーケンス番号、パーティションキー、データ BLOB で構成されます。これは GetRecords API によってデータストリーム内のレコードを取得することで確認できます。
GetRecords API のレスポンスに含まれるApproximateArrivalTimestampはデータストリームにデータが保存された時に、データストリーム側で付与するタイムスタンプを表しています。そのため処理遅延が発生した際の原因調査などに使用できそうです。
キャパシティモード
オンデマンドモードとプロビジョニングモードの2つのモードから選択可能です。 オンデマンドモードを選択する場面としては以下が考えられます。
- 書き込み 200 MiB/秒、200,000 レコード/秒、読み取り 400 MiB/秒以下
- 15分未満でトラフィックが以前のピークの2倍以上増加しない、またはその際に発生した書き込みスロットリングが許容できる
- リシャーディングに伴うデータ重複が許容できる(詳細は後述)
保持期間
デフォルトではデータ保持期間は24時間に設定されており、最長で8760時間(365日)まで保持することが可能です。 データストリームに保存されたデータを手動で削除することは不可能で、保持期間が経過した時のみデータが削除されます。
プロデューサー、コンシューマー
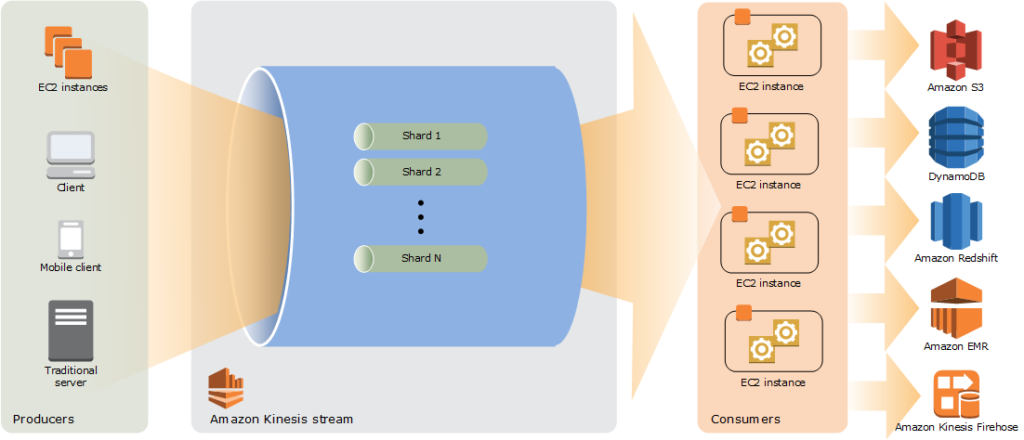
データストリームにデータを送るものをプロデューサー、データストリームからデータを取得するものをコンシューマーと呼びます。
シャード
データストリームを構成する単位で、データストリームの読み込み・書き込み性能はシャード数によって決まります。プロビジョニングモードを使用する場合、必要な性能に応じてリシャーディングを行い、適切にシャード数を保つことが必要になる。
リシャーディング
リシャーディングには、シャードの分割と結合という2種類のオペレーションがあります。シャードの分割では1つのシャードを2つシャードに分けます。シャードの結合では2つのシャードを1つのシャードに結合します。そのためリシャーディングに関して2つの性質をもちます。
- 1回の UpdateShardCount API によって変更可能なシャード数は現在のシャード数の0.5倍~2倍のシャード数に限定される
- リシャーディング後の目標シャード数(TargetShardCount)を現在のシャード数の25%の倍数にすることで、リシャーディングにかかる時間が最小限になる
リシャーディングが完了すると、親シャードに流れていたデータレコードは、データレコードのパーティションキーに基づいて、子シャードに流れるように再ルーティングされます。 リシャーディング前に親シャードにあったデータレコードは親シャードに残り続けるので、保持期間終了までは取得可能です。
リシャーディング後、ストリームが再び ACTIVE 状態になるとすぐに、子シャードからのデータの読み取りを開始できます。 ただし、リシャーディング後に残った親シャードには、リシャーディング前にストリームに追加されてまだ読み取られていないデータがそのまま格納されている可能性があるため、子シャードのデータから処理するとデータの順番が前後してしまいます。KCL を使用する場合は順序保証され、親シャードを処理した後に子シャードのデータを処理します。
パーティションキー
パーティションキーを使用して、データレコードを格納するシャードが決定されます。そのためパーティションキーに偏りが生じると、ホットシャードにつながり性能低下を招く可能性があります。
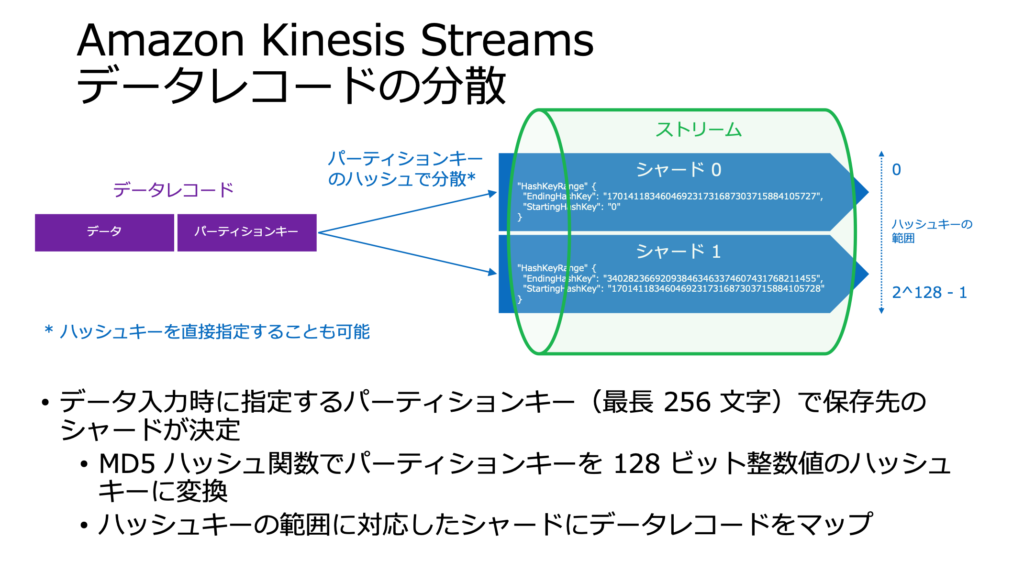
AWSでのストリーム処理入門より抜粋
クォータと制限
様々なクォータが存在します。詳細はクォータと制限 - Amazon Kinesis Data Streamsを参照ください。 個人的に特に注意が必要な点としては
- UpdateShardCount API は24時間以内に10回以上できないという制限があるため、日内で頻繁にシャード数を変更することはできない
- デフォルトのシャードクォータは、アカウントあたり500シャード 1000シャードまでは AWS Service Quotas からリクエスト後、すぐに制限値が引き上げられた
- 1000シャード以上はサポートから連絡があり、用途等を英語で説明した後に制限値が引き上げられた実績あり→数日間のリードタイムがかかることに注意
データストリームからの読み取り
Kinesis Client Library の使用
データストリームからデータを取得し処理する方法の一つが Kinesis Client Library(KCL)を使用することです。KCLに関しては以下の記事でまとめています。
https://poota.net/archives/603
重複レコードの処理
レコードが複数回配信される理由は、プロデューサーの再試行とコンシューマーの再試行の2パターンに分けられる。
プロデューサーの再試行
プロデューサーの再試行はコンシューマーの再試行と比べて発生する可能性が低いです。発生する場面としては、PutRecord API を呼び出した後、Kinesis Data Streams から応答を受け取る前に、ネットワーク関連エラーが発生した場合などが考えられます。 この重複を排除するためには、レコード内に主キーを埋め込み、データストリームから取得した後に排除する必要があります。
コンシューマーの再試行
コンシューマーの再試行は下記の場合に発生します。
- ワーカーが予期せず終了する
- ワーカーのインスタンスが追加または削除される
- シャードが結合または分割される
- アプリケーションがデプロイされる
ワーカーの増減およびシャード数の増減が発生した際に再試行が発生し、それに伴い重複レコードが発生します。 運用でワーカーの増減やシャード数の増減を行うシーンとしては、負荷量に応じて処理性能を調節する時などが考えられます。上記の仕様を考慮すると、取得後に重複レコードを排除することが難しく、重複レコードの存在が許容できない場合はワーカーおよびシャード数の増減を行う回数は最小限に留める運用を行う必要があります。
おわりに
公式ドキュメントの中から、Kinesis Data Streams を使用する際に注意が必要な点を整理してまとめました。この記事がどなたかの参考になれば幸いです。