はじめに
以前の記事で、LINE、AWS、Notion API を利用して、英単語を検索して意味をノートにメモする作業を自動化しました。これを利用して登録した単語を復習するために、Vue.js を使用したアプリケーションを作成したので、その手順についてまとめます。 以前の記事はこちら
https://poota.net/archives/567
環境
インフラにはAWSを使用しました。 バックエンドはAPI Gateway、Lambda を使用したサーバレス構成にしています。フロントエンドには Vue.js を使用し、S3 にホスティングしています。
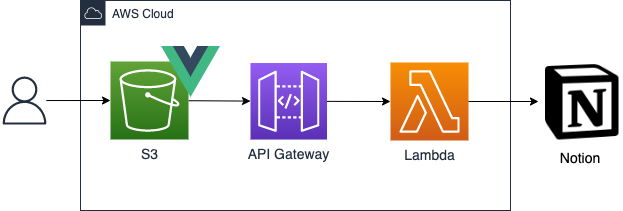
対象者
この記事は下記のような人を対象にしています。
- AWS と Vue.js、Notion を使用したWebアプリを作成したい人
手順
Notion
Notion に登録されているデータの確認
現在、Notion のデータベースには以下のように英単語が登録されています。 この状態のまま眺めていても覚えているかの確認ができないため、一問一答形式で勉強できるようにします。
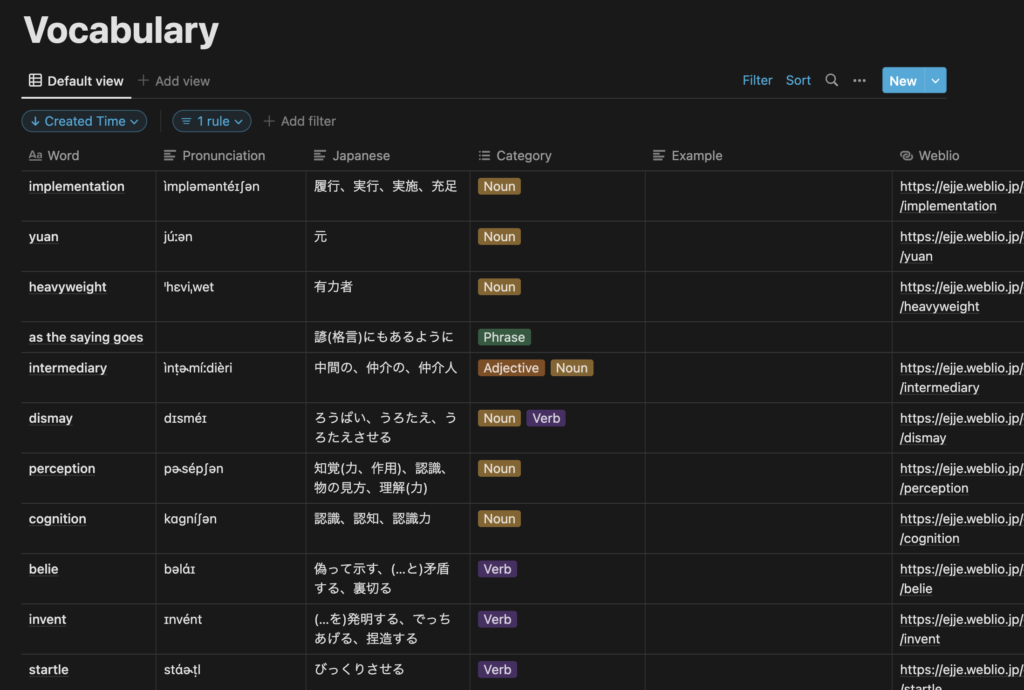
Notion API の設定
公式ドキュメントを参考に、Notion API の設定を行います。 Internal Integration Token は Notion API を叩く際に必要になるので、セキュアに保管してください。 今回は SSM パラメータストアに保存します。
データベース情報を取得
Notion API を使用してデータベースにレコードを作成するために、登録するデータベースの ID が必要です。 データベースの ID は Notion の URL から確認可能です。 今回は SSM パラメータストアに保存します。
https://www.notion.so/myworkspace/a8aec43384f447ed84390e8e42c2e089?v=...
|--------- Database ID --------|
CORS 設定要否
CORS の有効化を行う必要があるか以下の2点から判断します。詳細はREST API リソースの CORS を有効にする参照してください。
-
クロスオリジン HTTP リクエストリクエストか オリジンにはプロトコル、ドメイン(サブドメイン)、ポートの情報が含まれるため、これらのいずれか異なるリクエストの場合はクロスオリジンリクエスト
-
オリジンの例:https://www.google.com:443
-
単純な POST リクエストか クロスオリジン HTTP リクエストは、単純なリクエスト、および単純ではないリクエストの2種類に分類可能
-
単純なリクエストの条件についてはオリジン間リソース共有 (CORS) - HTTP | MDN
今回、クロスオリジン HTTP リクエストかつ、単純な POST リクエストではないため CORS の有効化を行う必要があります。また、Lambda 関数のレスポンスにおいても統合タイプに応じて設定が必要になります。
Lambda
Lambda 関数
下記のプログラムを登録に使用しました。
-
Notion に対するクエリ操作で取得できるアイテムの最大件数は100件であるため、レスポンスボディに含まれる
has_more、next_cursorを利用して再帰的にクエリを実施 -
Lambda プロキシ統合で CORS を有効にするため Lambda 関数は下記をヘッダーに入れてリターン(REST API リソースの CORS を有効にする)
'Access-Control-Allow-Origin': 'http://{S3バケット名}.s3-website-ap-northeast-1.amazonaws.com' -
'Access-Control-Allow-Methods': 'OPTIONS,POST,GET' -
S3 にホストするので、許可するオリジンには http://{S3バケット名}.s3-website-ap-northeast-1.amazonaws.com を指定
import json
import query_item
def lambda_handler(event, context):
items = query_item.query_item()
return {
'statusCode' : 200,
'body' : json.dumps(items),
'headers': {
'Access-Control-Allow-Headers': '*',
'Access-Control-Allow-Origin': 'http://{S3バケット名}.s3-website-ap-northeast-1.amazonaws.com',
'Access-Control-Allow-Methods': 'OPTIONS,POST,GET'
}
}
import boto3
from notion_client import Client
#SSM
ssm = boto3.client('ssm')
notion_token: str = ssm.get_parameter(Name='/linebot/vocabulary/notion_token',WithDecryption=True)['Parameter']['Value']
database_id: str = ssm.get_parameter(Name='/linebot/vocabulary/database_id',WithDecryption=True)['Parameter']['Value']
notion = Client(auth=notion_token)
def parse_item(items, res):
for result in res['results']:
try:
item = {}
item['Word'] = result['properties']['Word']['title'][0]['plain_text']
item['Japanese'] = result['properties']['Japanese']['rich_text'][0]['plain_text']
items.append(item)
except IndexError:
pass
return items
def query_item(items=[], cnt=0, next_cursor=None):
print(f'cnt:{cnt}, next_cursor:{next_cursor}')
param = {"database_id" : database_id} if cnt == 0 else {"database_id" : database_id, "start_cursor" : next_cursor}
res = notion.databases.query(**param)
items = parse_item(items, res)
has_more = res['has_more']
next_cursor = res['next_cursor']
if has_more:
cnt += 1
return query_item(items, cnt, next_cursor)
return items
if __name__ == '__main__':
query_item()
Lambda レイヤー
Lambda 関数内の処理で使用するライブラリ(notion-client)の Lambda レイヤーを作成します。 Lambda レイヤーの作成に関しては過去にまとめていますので、そちらを参考にしてください。
https://poota.net/archives/414
API Gateway
統合タイプは Lambda プロキシ統合を選択し、上記ステップで作成した Lambda 関数を統合先に設定します。 公式ドキュメントに従って CORS 有効化を行います。設定が完了すると OPTIONS メソッドが作成されます。設定を反映させるため、忘れずに API のデプロイを行います。
Vue.js によるアプリケーション画面の作成
Vue 3 の単一ファイルコンポーネント(SFC)を使って記述しました。詳細はSFC 構文の仕様 | Vue.jsを参照。
- 画面読み込み時に API Gateway のエンドポイントにリクエスト
- デフォルトでは直近登録された単語から順に出題するが、シャッフルボタンによりランダムに出題させることが可能
- UI は Vuetify で作成
import { ref, reactive } from 'vue';
const data = ref(0);
const index = ref(0);
const isStarted = ref(false);
const isAnswered = ref(false);
const url = '{API Gateway のエンドポイント}';
async function resJson () {
const res = await window.fetch(url);
const res_data = await res.json();
data.value = res_data;
console.log(data);
}
resJson();
const shuffle = ([...array]) => {
for (let i = array.length - 1; i >= 0; i--) {
const j = Math.floor(Math.random() * (i + 1));
[array[i], array[j]] = [array[j], array[i]];
}
return array;
}
const previousButton = () => {
isAnswered.value = false;
index.value -= 1;
};
const nextButton = () => {
isAnswered.value = false;
index.value += 1;
};
const answerButton = () => {
isAnswered.value = true;
};
開始
シャッフル
前の問題
次の問題
答え
{{ data[index].Word }}
{{ data[index].Japanese }}
#app {
font-family: Avenir, Helvetica, Arial, sans-serif;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
text-align: center;
color: #2c3e50;
margin-top: 60px;
}
ビルドしたファイルを S3 にデプロイすれば、準備は完了です。 S3 の設定についてはAmazon S3 を使用して静的ウェブサイトをホスティングする - Amazon Simple Storage Service参照。
動作確認
S3 のバケットウェブサイトエンドポイントにアクセスすると登録した単語の問題が出題されることが確認できました。
おわりに
登録およびWebアプリの全体構成はこちらです。
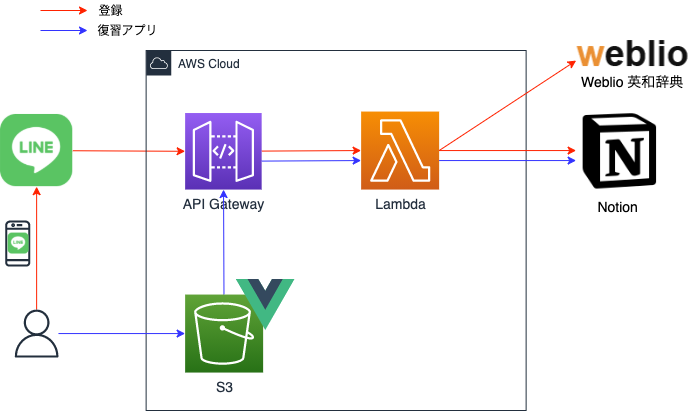
今回は Notion に登録した単語を復習するために、Vue.js を使用したアプリケーションを作成しました。この記事がどなたかの参考になれば幸いです。